Introduction
ramen provides plot() methods for all three
core classes: ConsortiumMetabolism,
ConsortiumMetabolismSet, and
ConsortiumMetabolismAlignment. This vignette is a visual
gallery of every plot type. For context on the underlying analyses, see
vignette("ramen", package = "ramen") and
vignette("alignment", package = "ramen").
All ramen plot methods return ggplot
objects, composable with the usual ggplot2 operators
(e.g. + ggplot2::theme_minimal()). Network plots are
rendered with the ggraph package.
Example data
data("misosoup24")
cm_list <- lapply(seq_len(6), function(i) {
ConsortiumMetabolism(
misosoup24[[i]],
name = names(misosoup24)[i]
)
})
cms <- ConsortiumMetabolismSet(cm_list, name = "Demo")
cma_pair <- align(cm_list[[1]], cm_list[[2]])
cma_mult <- align(cms)ConsortiumMetabolism plots
plot(CM) renders a directed metabolic flow network using
ggraph. Nodes are coloured by role:
lightblue for sources (only outgoing edges),
salmon for sinks (only incoming edges), and
lightgoldenrod for intermediate nodes (both incoming
and outgoing). The type argument selects which assay matrix
determines edge weights.
Binary network
The default view shows network structure with uniform edge weights.
plot(cm_list[[1]], type = "Binary")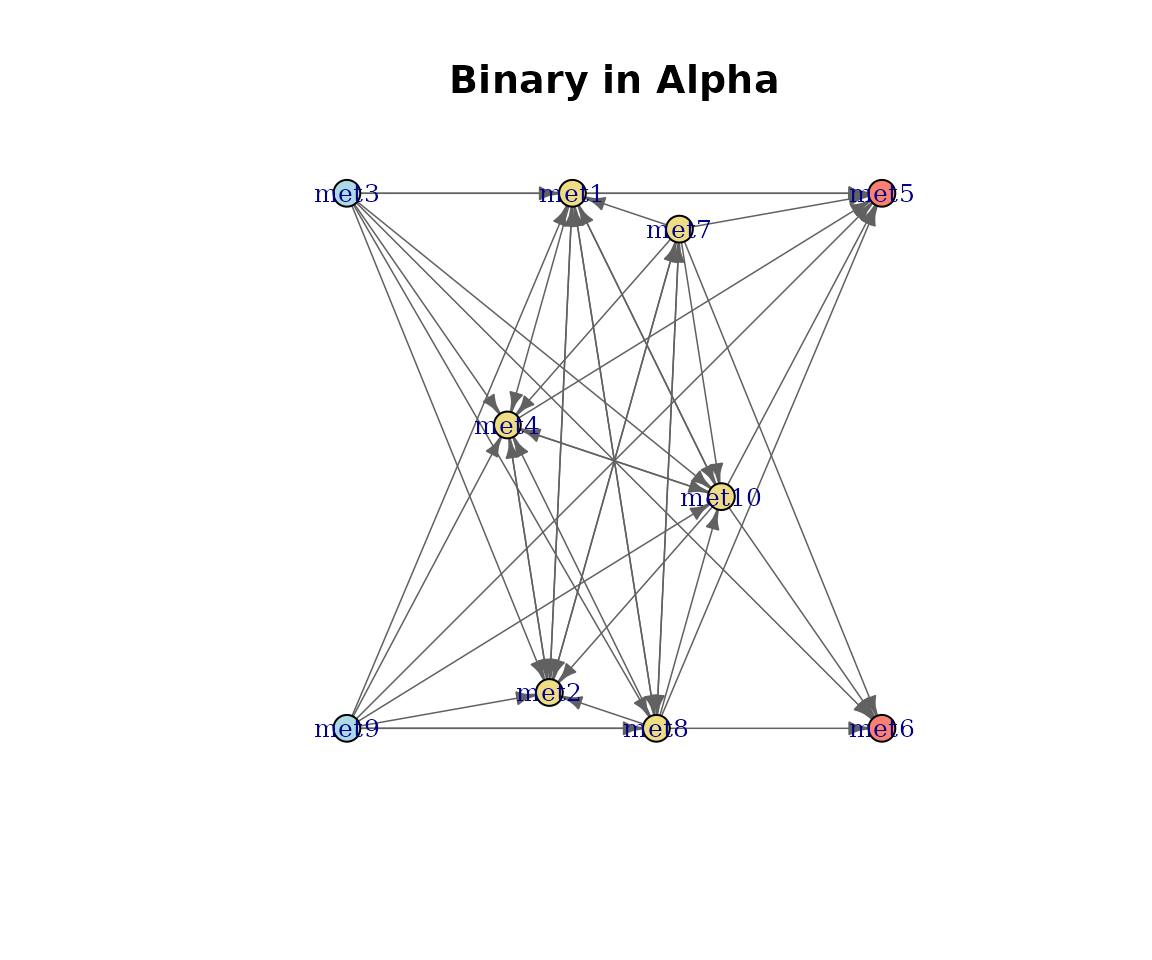
Binary metabolic network.
Number of species per pathway
Edge weights reflect how many species catalyse each pathway.
plot(cm_list[[1]], type = "nSpecies")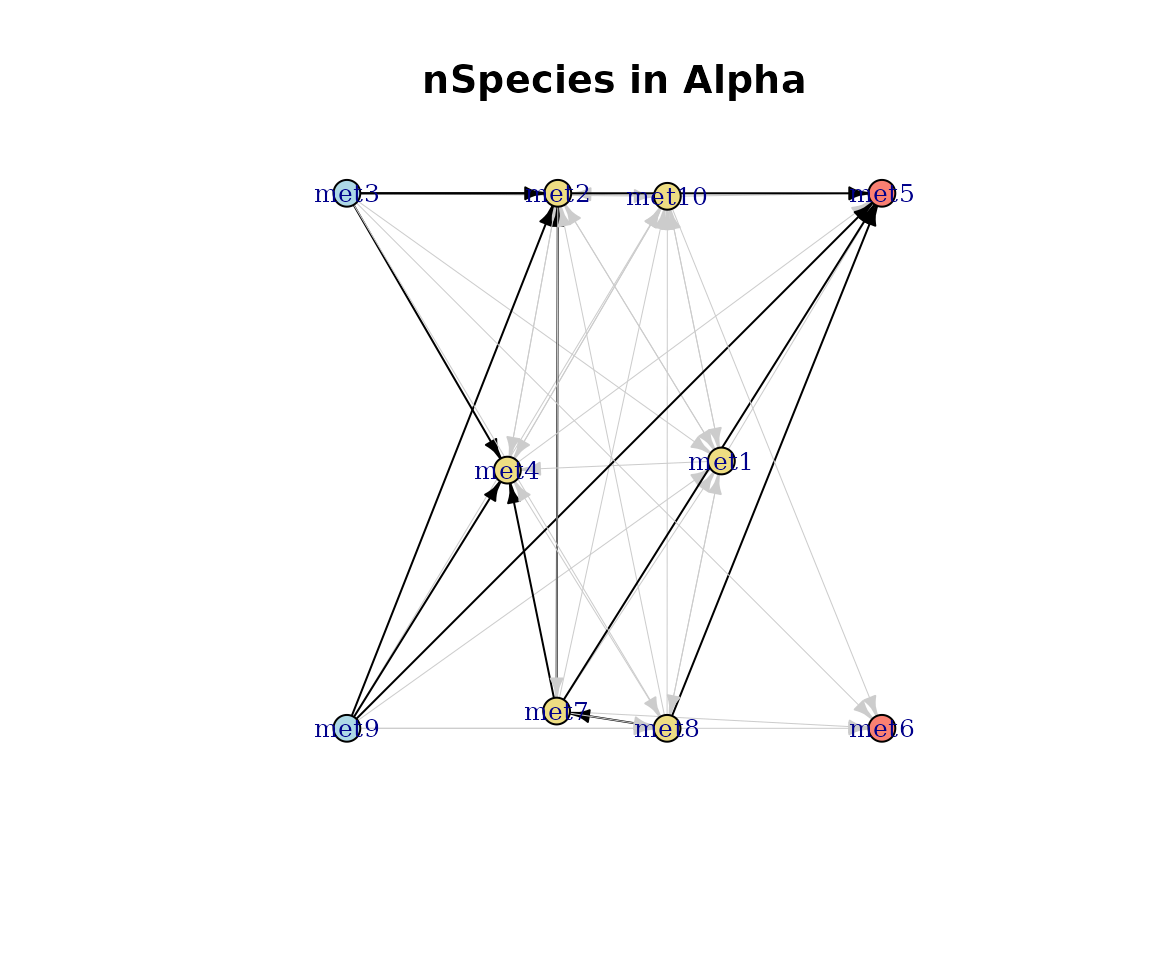
nSpecies-weighted network.
Consumption and production
Edges weighted by summed flux magnitudes.
plot(cm_list[[1]], type = "Consumption")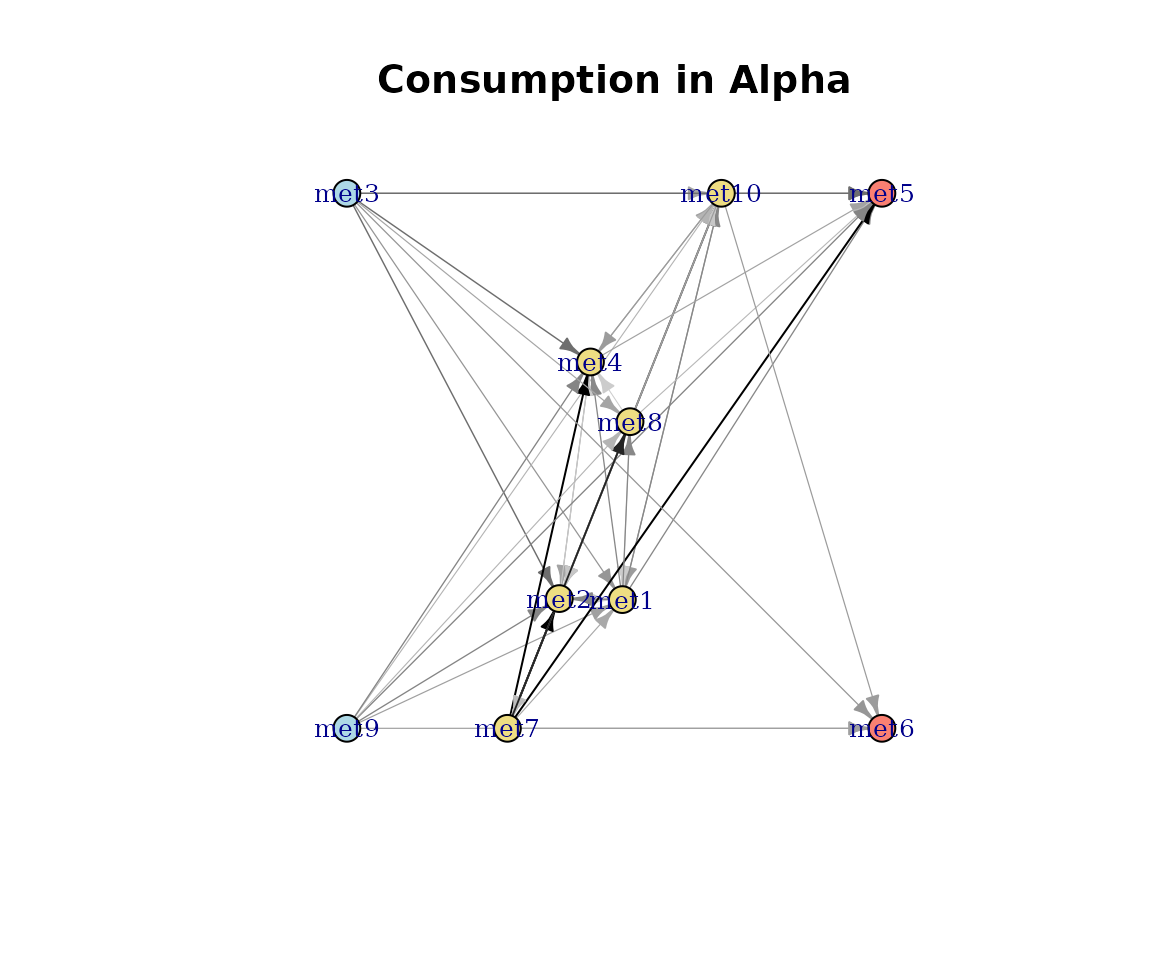
Consumption-weighted network.
plot(cm_list[[1]], type = "Production")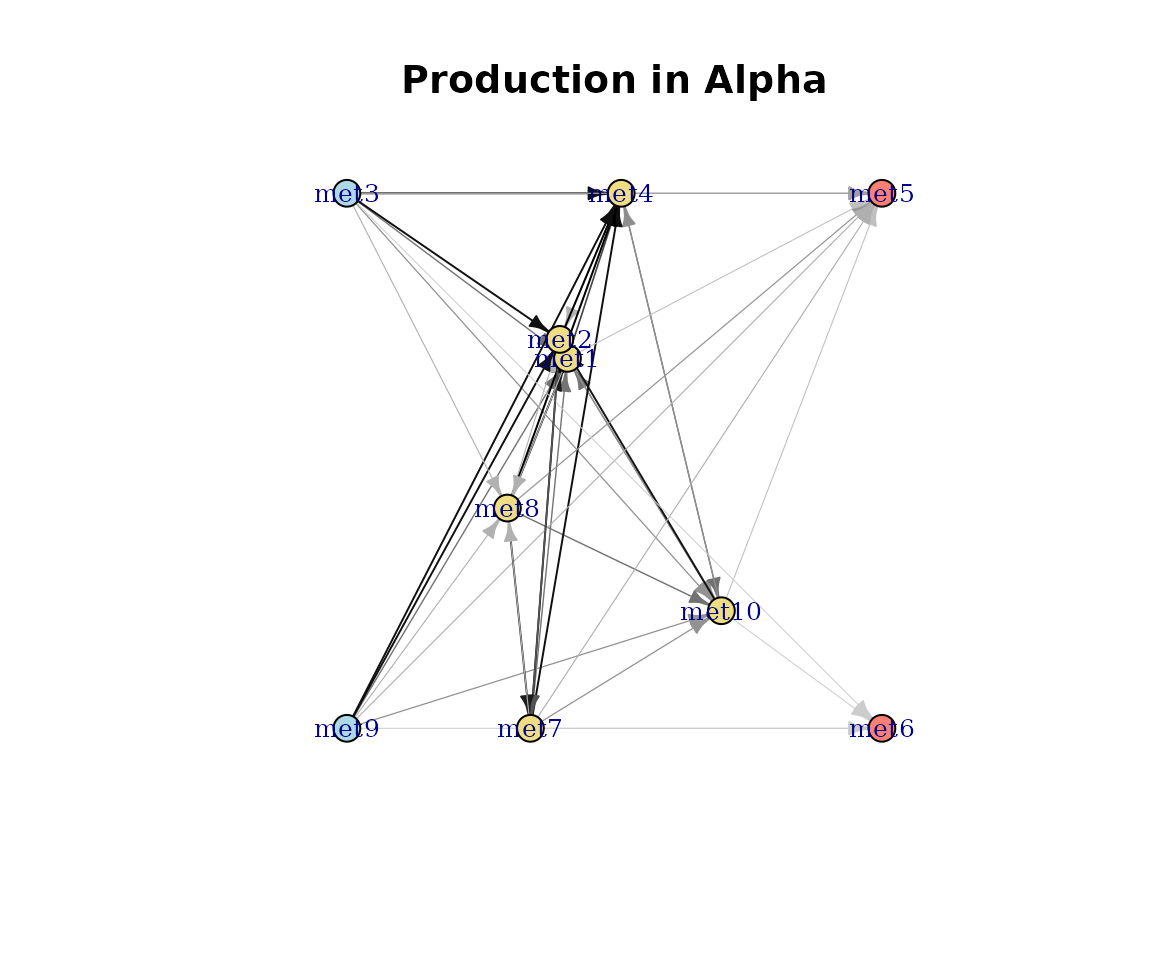
Production-weighted network.
Effective consumption and production
Effective diversity measures how evenly species contribute to each pathway (Shannon-based effective number of species).
plot(cm_list[[1]], type = "EffectiveConsumption")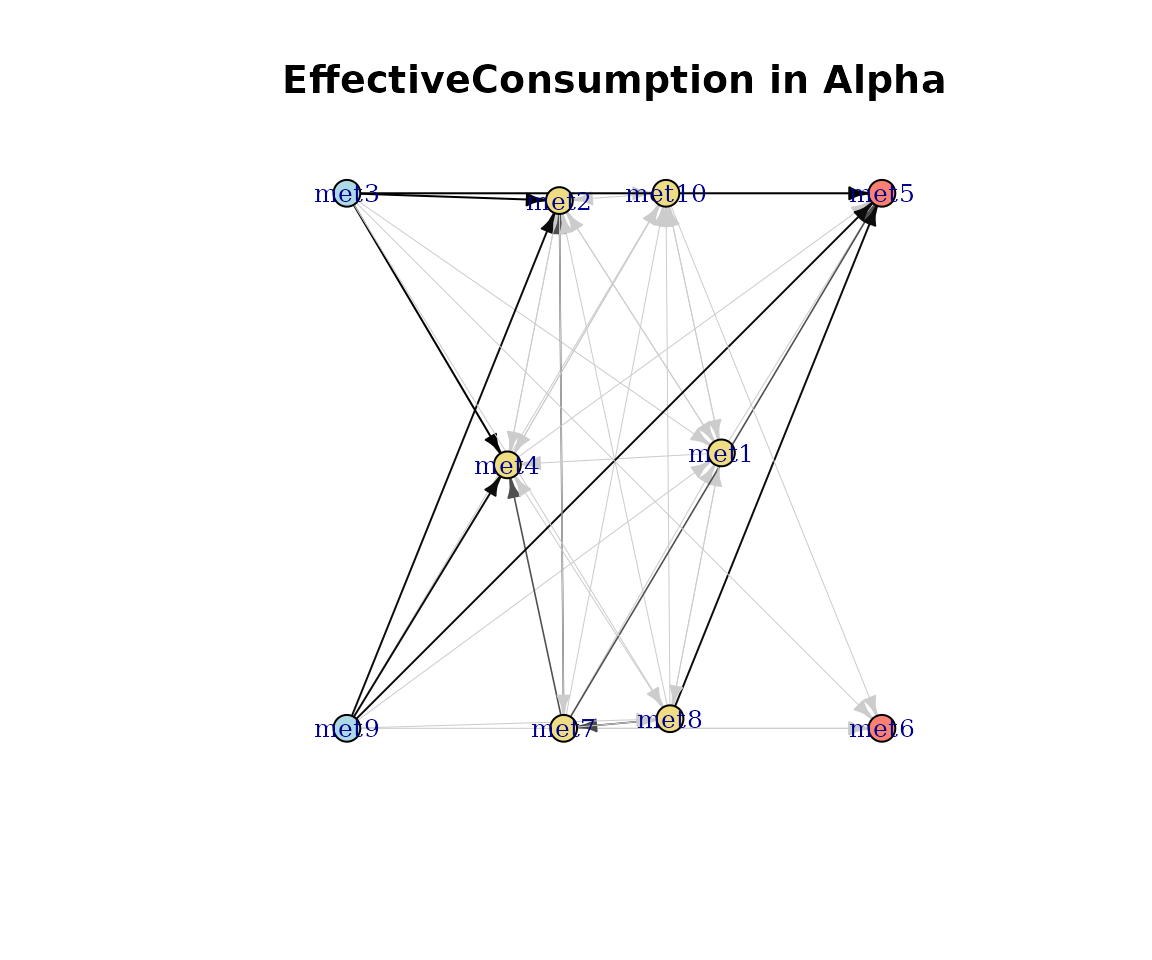
Effective consumption network.
plot(cm_list[[1]], type = "EffectiveProduction")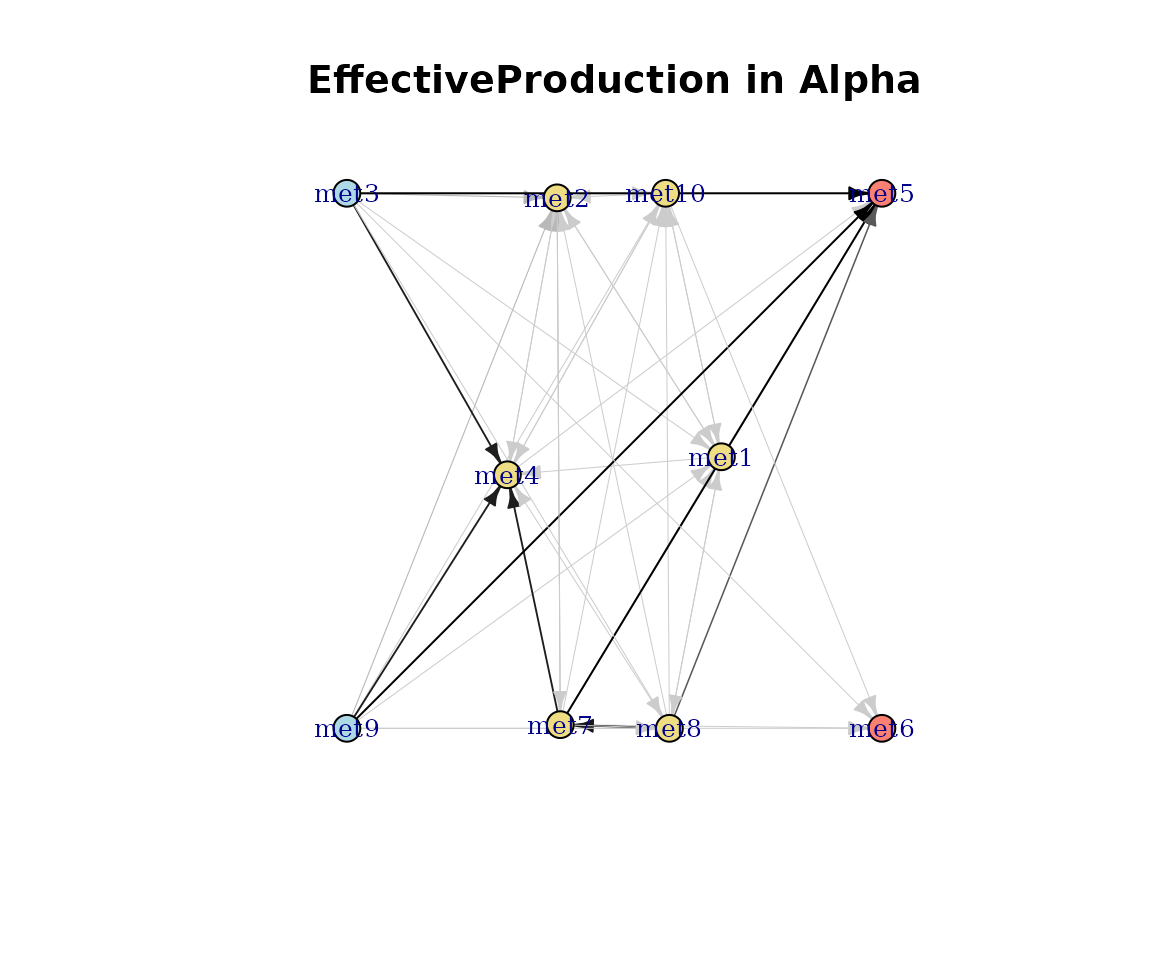
Effective production network.
ConsortiumMetabolismSet plots
Dendrogram
plot(CMS) draws a hierarchical clustering dendrogram
with numbered internal nodes. These node IDs are used by
extractCluster() to pull sub-clusters.
plot(cms)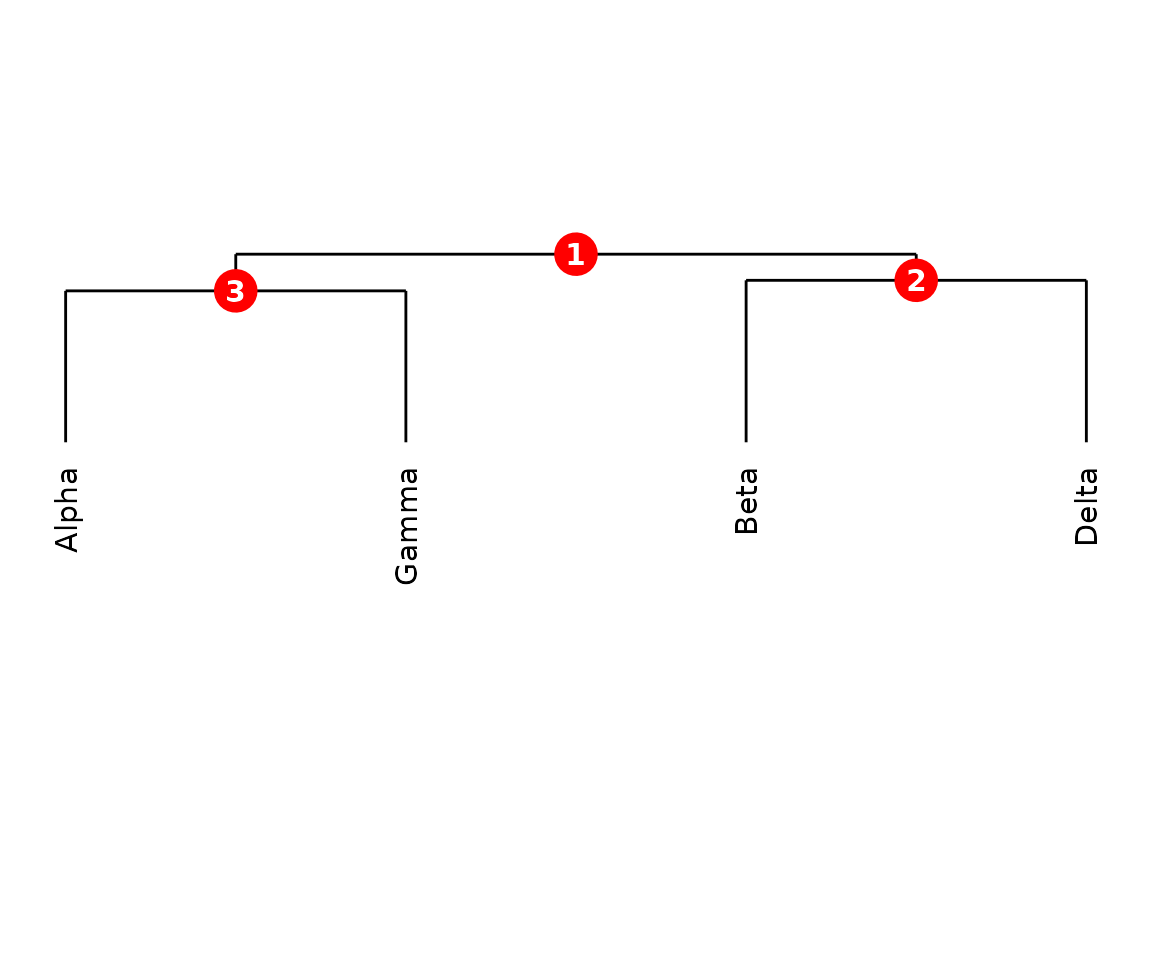
CMS dendrogram with numbered nodes.
Custom label colours
Supply a data.frame mapping leaf labels to colours.
colour_map <- data.frame(
label = names(misosoup24)[seq_len(6)],
colour = c(
"steelblue", "firebrick", "forestgreen",
"darkorange", "purple", "darkred"
)
)
plot(cms, label_colours = colour_map)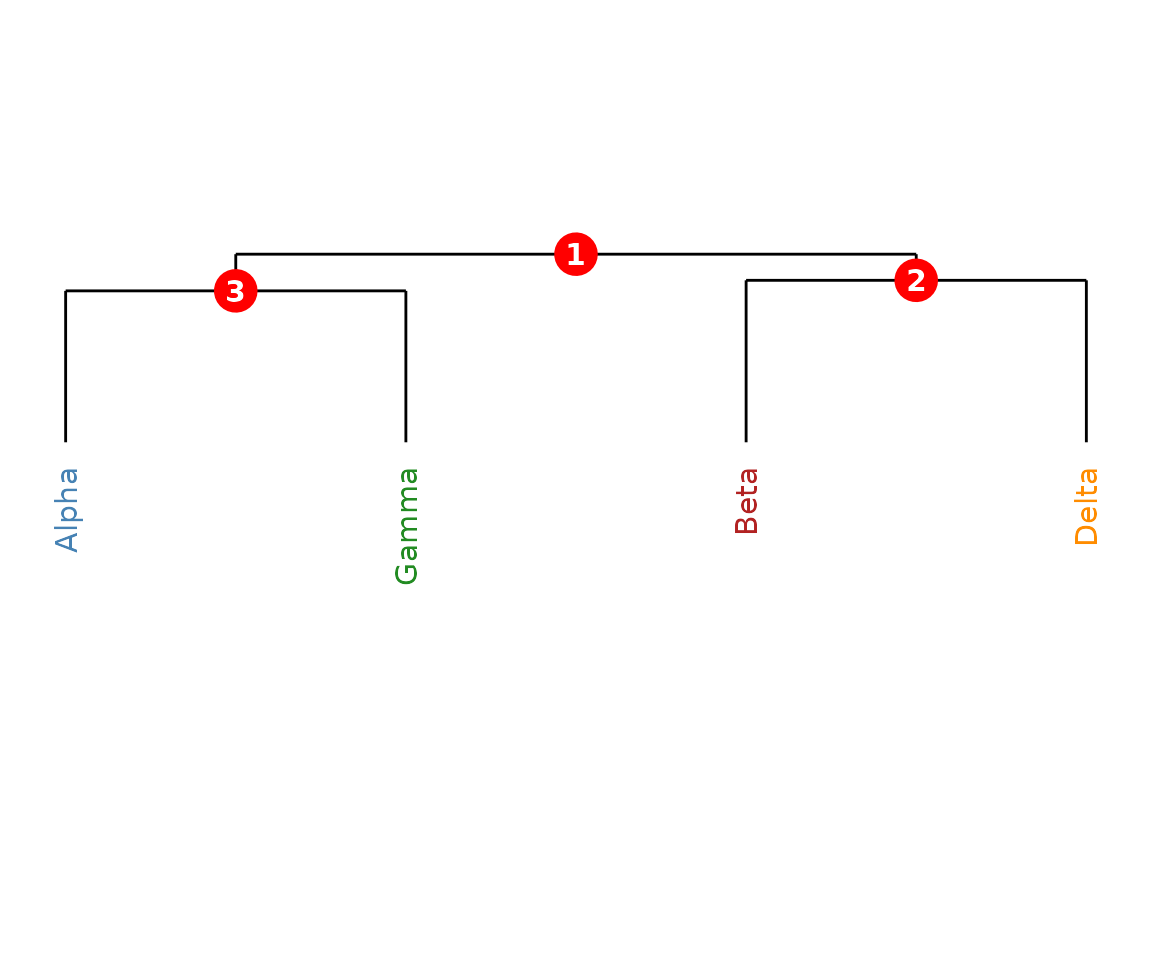
CMS dendrogram with coloured labels.
ConsortiumMetabolismAlignment plots
The CMA plot() method supports three types:
"heatmap", "network", and
"scores". The default is "network" for
pairwise and "heatmap" for multiple alignments.
Heatmap (multiple alignment)
Pairwise FOS similarities with dendrogram-based ordering. Values range from 0 (no overlap) to 1 (identical).
plot(cma_mult, type = "heatmap")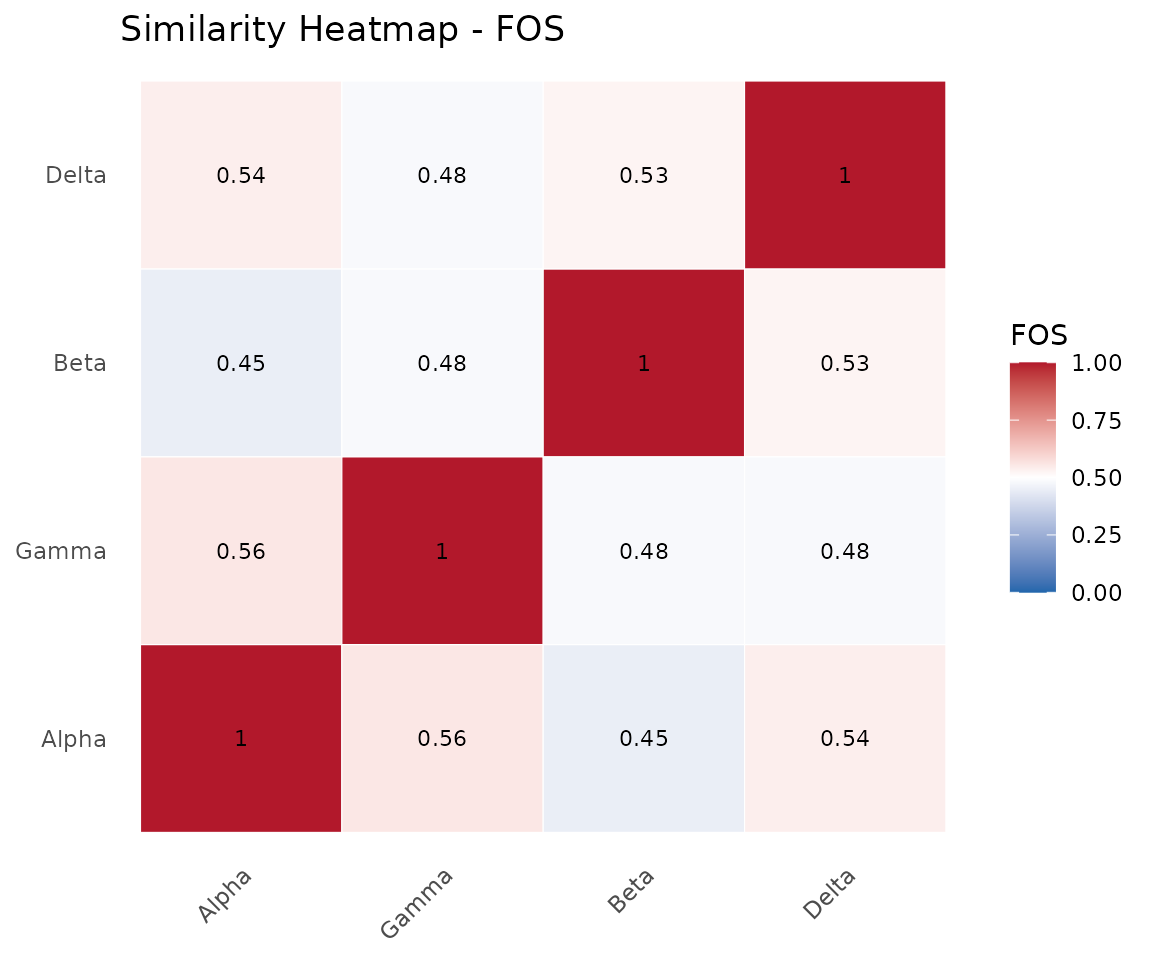
Similarity heatmap.
Network (pairwise alignment)
Shared, query-unique, and reference-unique pathways are coloured using the colour-blind-safe Okabe-Ito palette (bluish-green, blue, vermilion). The legend is titled Pathway type.
plot(cma_pair, type = "network")
Pairwise alignment network.
Using plotDirectedFlow() directly
For fine-grained control over the network layout, call
plotDirectedFlow() directly on an igraph object. This is
the function underlying all CM and CMA network plots.
g <- igraph::graph_from_adjacency_matrix(
SummarizedExperiment::assay(cm_list[[2]], "nSpecies"),
mode = "directed",
weighted = TRUE
)
plotDirectedFlow(
g,
colourEdgesByWeight = TRUE,
edgeWidthRange = c(0.5, 2),
nodeSize = 8,
nodeLabelSize = 3.5,
main = paste0(name(cm_list[[2]]), " - nSpecies (custom)")
)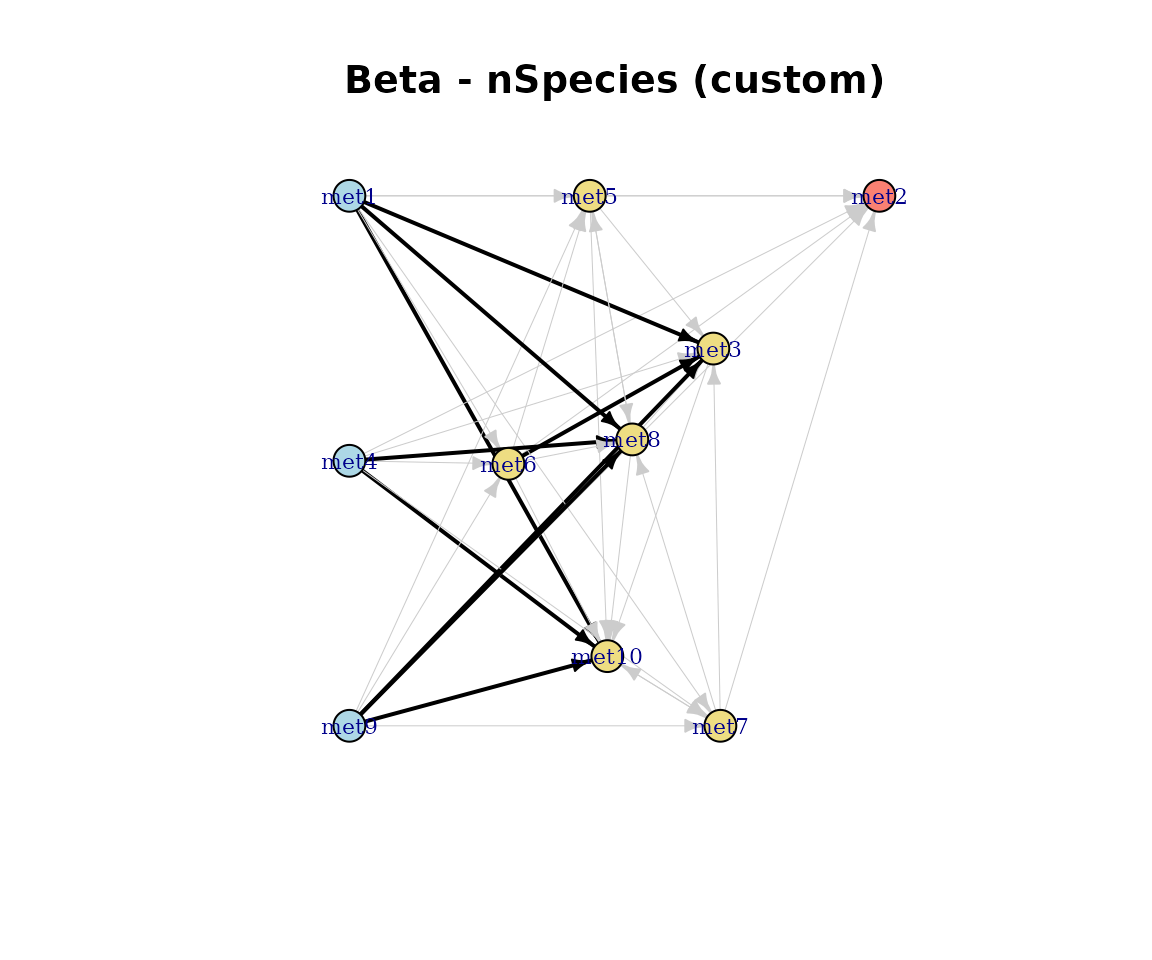
Custom directed flow plot.
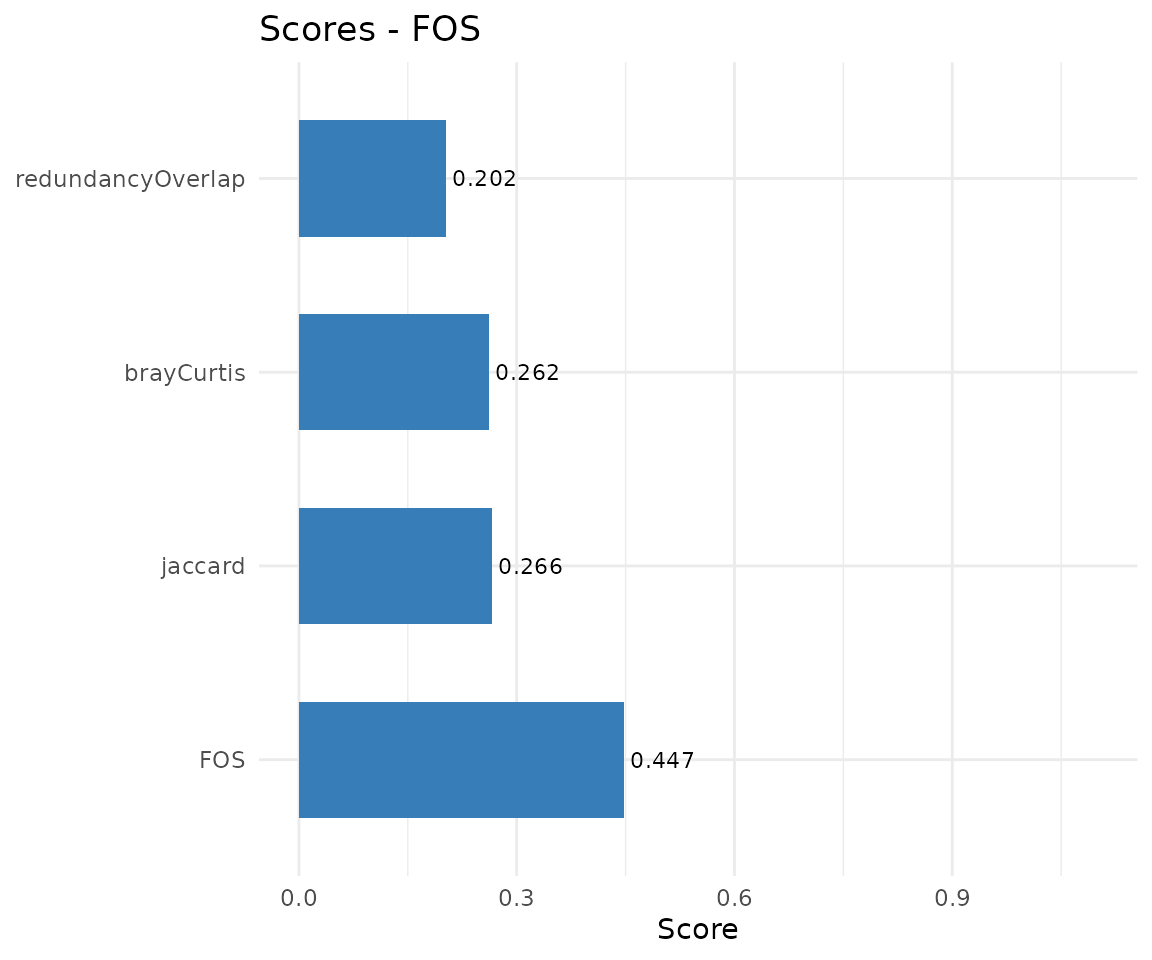
Plot type summary
| Object class |
type argument |
Description |
|---|---|---|
| CM |
"Binary" (default) |
Directed network, unweighted |
| CM | "nSpecies" |
Pathways weighted by species count |
| CM | "Consumption" |
Pathways weighted by consumption flux |
| CM | "Production" |
Pathways weighted by production flux |
| CM | "EffectiveConsumption" |
Effective consuming species |
| CM | "EffectiveProduction" |
Effective producing species |
| CMS | (none) | Dendrogram with numbered nodes |
| CMA | "heatmap" |
Pairwise similarity heatmap |
| CMA | "network" |
Shared/unique pathway graph |
| CMA | "scores" |
Bar chart of similarity metrics |
Session info
sessionInfo()
#> R version 4.6.0 (2026-04-24)
#> Platform: x86_64-pc-linux-gnu
#> Running under: Ubuntu 24.04.4 LTS
#>
#> Matrix products: default
#> BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
#> LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
#>
#> locale:
#> [1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
#> [4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
#> [7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
#> [10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
#>
#> time zone: UTC
#> tzcode source: system (glibc)
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] ramen_0.99.0 BiocStyle_2.40.0
#>
#> loaded via a namespace (and not attached):
#> [1] tidyselect_1.2.1 viridisLite_0.4.3
#> [3] dplyr_1.2.1 farver_2.1.2
#> [5] viridis_0.6.5 Biostrings_2.80.0
#> [7] S7_0.2.2 ggraph_2.2.2
#> [9] fastmap_1.2.0 SingleCellExperiment_1.34.0
#> [11] lazyeval_0.2.3 tweenr_2.0.3
#> [13] digest_0.6.39 lifecycle_1.0.5
#> [15] tidytree_0.4.7 magrittr_2.0.5
#> [17] compiler_4.6.0 rlang_1.2.0
#> [19] sass_0.4.10 tools_4.6.0
#> [21] igraph_2.3.1 yaml_2.3.12
#> [23] knitr_1.51 labeling_0.4.3
#> [25] graphlayouts_1.2.3 S4Arrays_1.12.0
#> [27] DelayedArray_0.38.1 RColorBrewer_1.1-3
#> [29] TreeSummarizedExperiment_2.20.0 abind_1.4-8
#> [31] BiocParallel_1.46.0 withr_3.0.2
#> [33] purrr_1.2.2 BiocGenerics_0.58.0
#> [35] desc_1.4.3 grid_4.6.0
#> [37] polyclip_1.10-7 stats4_4.6.0
#> [39] ggplot2_4.0.3 scales_1.4.0
#> [41] MASS_7.3-65 SummarizedExperiment_1.42.0
#> [43] cli_3.6.6 rmarkdown_2.31
#> [45] crayon_1.5.3 ragg_1.5.2
#> [47] treeio_1.36.1 generics_0.1.4
#> [49] ape_5.8-1 cachem_1.1.0
#> [51] ggforce_0.5.0 parallel_4.6.0
#> [53] BiocManager_1.30.27 XVector_0.52.0
#> [55] matrixStats_1.5.0 vctrs_0.7.3
#> [57] yulab.utils_0.2.4 Matrix_1.7-5
#> [59] jsonlite_2.0.0 bookdown_0.46
#> [61] IRanges_2.46.0 S4Vectors_0.50.0
#> [63] ggrepel_0.9.8 systemfonts_1.3.2
#> [65] dendextend_1.19.1 tidyr_1.3.2
#> [67] jquerylib_0.1.4 glue_1.8.1
#> [69] pkgdown_2.2.0 codetools_0.2-20
#> [71] gtable_0.3.6 GenomicRanges_1.64.0
#> [73] tibble_3.3.1 pillar_1.11.1
#> [75] rappdirs_0.3.4 htmltools_0.5.9
#> [77] Seqinfo_1.2.0 R6_2.6.1
#> [79] textshaping_1.0.5 tidygraph_1.3.1
#> [81] evaluate_1.0.5 lattice_0.22-9
#> [83] Biobase_2.72.0 memoise_2.0.1
#> [85] bslib_0.10.0 Rcpp_1.1.1-1.1
#> [87] gridExtra_2.3 SparseArray_1.12.2
#> [89] nlme_3.1-169 xfun_0.57
#> [91] fs_2.1.0 MatrixGenerics_1.24.0
#> [93] pkgconfig_2.0.3